
2005-01-05 20:07:59
Chapter 6: History
This is part of an online book called Source Control HOWTO, a best practices guide on source control, version control, and configuration management.
| < Chapter 5 | Chapter 7 > |
Confronting your past
You may now be tired of hearing me say it, but I will say it again: Your repository contains every version of everything which has ever been checked in to the repository. This is a Good Thing. We sleep better at night because we know that our efforts are always additive, never subtractive. Nothing is ever lost. As the team regularly checks in more stuff, the complete historical record is preserved, just in case we ever need it.
But this feature is also a Bad Thing. It turns out that keeping absolutely everything isn't all that useful if you can't find anything later.
My woodshop is a painfully vivid illustration of this problem. I have a habit of never throwing anything away. When I build a piece of furniture, I save every scrap of wood, telling myself that I might need it someday. I keep every screw, nail, bolt or nut, just in case I ever need it. But I don't organize these things very well. So when the time comes that I need something, I usually can't find it. I'm not necessarily proud of this confession, but my workshop stands as an expression of who I am. Those who love me sometimes find my habits to be endearing.
But there is nothing endearing about a development team that can't find something when they need it. A good SCM tool must do more than just keep every version of everything. It must also provide ways of searching and viewing and sorting and organizing and finding all that stuff.
In the rest of this chapter, I will discuss several mechanisms that SCM tools provide to help make the historical data more useful.
Labels
Perhaps the most important feature for dealing with old versions is the notion of a "label". In CVS, this feature is called a "tag". By either name, the concept is the same -- labels offer the ability to associate a name with a specific version of something in the repository. A label assigns a meaningful symbolic name to a snapshot of your code so you can later find that snapshot more easily.
This is not altogether different from the descriptive and memorable names we use for variables and constants in our code. Which of the following two lines of code is easier to understand?
if (errorcode == ERR_FILE_NOT_FOUND)
if (e == -43)
Similarly, which of the following is a more intuitive description of a specific version of your code?
LAST_VERSION_BEFORE_COREY_FOULED_EVERYTHING_UP
378
We create (or "apply") a label by specifying a few things:
- The string for the name of the label. This should be something descriptive that you can either remember or recognize later. Don't be afraid to put enough information in the name of the label. Note that CVS has strict rules for the syntax of a tag name (must start with a letter, no spaces, almost no punctation allowed). I still follow that tradition even though Vault is more liberal.
- The folder to which the label will be applied. (You can apply a label or tag to a single file if you want, but why? Like most source control operations, labels are most useful when applied recursively to a whole folder.)
- Which versions of everything should be included in the snapshot. Often this is implicitly understood to be the latest version, but your SCM tool will almost certainly allow you to label something in the past. If it won't, take it out back and shoot it.
- A comment explaining the label. This is optional, and not all SCM tools support it, (CVS doesn't), but a comment can be handy when you want to explain more than might be appropriate to say in the name of the label. This is particularly handy if your team has strict rules for the syntax of label (V1.3.2.1426.prod) which prevent you from putting in other information you need.
For example, in the following screen dump from Vault, I am labeling version 155 of the folder $/src/sgd/libsgdcore:
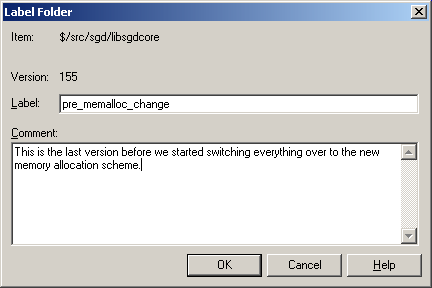
It is worth clarifying here that labels play a slightly different role in some SCM tools. In Subversion or Vault, folders have version numbers. Using the example from my screen dump above, the folder $/src/sgd/libsgdcore is at version 155. Each of the various files inside that folder has its own version number, but every time one of those files changes, the version number of the folder is increased by one as well. So the version number of a folder is a little bit like a label because it maps to a specific snapshot of the contents of the folder.
However, CVS doesn't work this way. There is no folder version number which can be mapped to a specific snapshot of the contents of that folder. For this reason, tags are all the more important in CVS, since there is no other way to easily mark specific versions of multiple items as a snapshot.
When to use a label
Labels are cheap. They don't consume a lot of resources. Your SCM tool won't slow down if you use lots of them. Having more labels does not increase your responsibilities. So you can use them as often as you like. The following situations are examples of when you might want to use a label:
When you make a release
A release is the most obvious time to apply a label. When you release a version of your application to customers, it can be very important to later know exactly which version of the code was released.
When something is about to change
Sometimes it is necessary to make a change which is widespread or fundamental. Before destabilizing your code, you may want to apply a label so you can easily find the version just before things started getting messed up.
When you do an automated build
Some automated build systems apply a label every time a build is done. The usual approach is to first apply the label and then do a "get by label" operation to retrieve the code to be used for the build. Using one of these tools can result in an awful lot of labels, but I still like the idea. It eliminates the guesswork of trying to figure out exactly which code was in the build.
When you move some changes from one place to another
Labels are handy ways to mark the sync points between two branches or two copies of the same tree. For example, suppose your company has two groups with separate source control systems. Group A has a library called SuperDuperNeatoUtilityLib. Group B uses this library as well, but they keep their own copy in the their own source control repository. Every so often, they login into Group A's repository and see if there are any bug fixes they want to migrate into their own copy. By applying a label to Group A's repository, they can more easily remember the latest point at which their two versions were in sync.
Best Practice: Use labels often
Labels are very lightweight. Don't hesitate to use them as often as you want.
Once you have a label, the question is what you can do with it. The truth is that some labels never get used. That's okay. Like I said, they're cheap.
But many labels do get used. The "get by label" operation is the most common way that a label comes in handy. By specifying a label as the version you want to retrieve, you can get a copy of every file exactly as it was when the label was created.
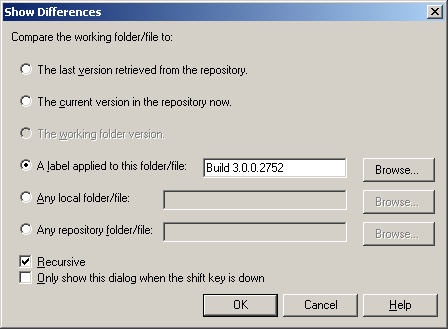
It's also very handy to diff against a label. For example, in the following screendump from Vault, I am asking to see all the differences between the contents of my working folder and the contents of the label named "Build 3.0.0.2752". (This label was applied by our automated build system when it made build 2752.)
Admonishments on the evils of "Label Promotion"
Sometimes after you apply a label you realize that you want to make a small change. As an example, consider the following scenario: One week ago, you finalized the code for the 4.0 release of your product. You applied a label to the tree, and your team has proceeded with development on a few post-4.0 tasks.
But now Bob (one of your QA guys) comes crawling into your office. His clothes are torn and his face is covered with soot. While gasping for air he informs you that he has found a potential showstopper bug in the 4.0 release candidate. Apparently if you are running your app on the Elbonian version of Windows NT 3.5 with the time zone set to Pacific Standard Time and you enter a page margin size of 57 inches while printing a 42 page document on a Sunday morning before 9am, the whole machine locks up. In fact, if you don't quickly kill the app, the computer will soon burst into flame.
As Bob finishes explaining the situation, a developer walks in and announces that he has already found the fix for this bug, and it affects only one line of code in FOO.CPP. Should he make the fix and generate a new release candidate?
After scolding Bob for not being more diligent in finding this bug sooner, you begrudgingly decide that the severity of this bug does indeed make it a showstopper for the 4.0 release. But how to proceed? The label for the 4.0 build has already been applied. You want a new release candidate which contains exactly the contents of the 4.0 label plus this one-line change. None of the other stuff which has been checked in during the past week should be included.
I'm sure it was this very situation which prompted Microsoft to implement a feature in SourceSafe 6.0 called "label promotion". The idea is that a minor change to a label can be made after it was originally created. Returning to our example, let's suppose that the 4.0 label contained version 6 of FOO.CPP. So now we would make the one-line change and check it in, resulting in version 7 of that file. Then we "promote" version 7 of the file to be included in the 4.0 label, instead of version 6.
Best Practice: Avoid using label promotion
Your repository should contain an accurate reflection of what really happened. Don't use label promotion. If you must, do at least try to feel guilty about it.
Personally I think "label promotion" is a terrible name for this feature. In fact, I think label promotion is a terrible feature. I am doctrinally opposed to any SCM feature which allows the user to alter the historical record. The history of the repository should be a complete record of what really happened. If we use label promotion in this situation, there will be no record of the fact that the original 4.0 release candidate actually contained version 6 of that file. In situations where label promotion seems necessary, a fanatical purist like me would just create a new branch, which is a topic I will discuss in the next chapter.
However, even though I dislike this feature for philosophical reasons, customers really want it. Here at SourceGear, I tell people that "the customer is not always right, but the customer is always the customer". So in order to remain true to our goal of making Vault a painless transition from SourceSafe, we implemented label promotion. But that doesn't mean I have to be happy about it.
History
Another important feature is the ability to view and browse historical versions of the repository. In its simplest form, this can be just a list of changes with the following information about each change:
- What was changed
- When the change was made
- Who did it
- Why (the comment entered at checkin time)
But without a way of filtering and sorting this information, using history is like trying to take a drink from a fire hose. Fortunately, most SCM tools provide plenty of flexibility in helping you see the data you need.
In CVS, history is obtained using the 'cvs log' command. In the Vault GUI client, we use the History Explorer. In either case, the first way to filter history is to decide where to invoke the command. Requesting the full history from the root folder of a repository is like the aforementioned fire hose. Instead, invoke the command on a subfolder or even on a file. In this way, you will only see the changes which have been made to the item you selected.
Most SCM tools provide other ways of filtering history information as well:
- Show only changes made during a specific range of dates
- Show only changes made by a specific user
- Show only changes made to files of a certain extension
- Show only changes where the checkin comment contains specific words
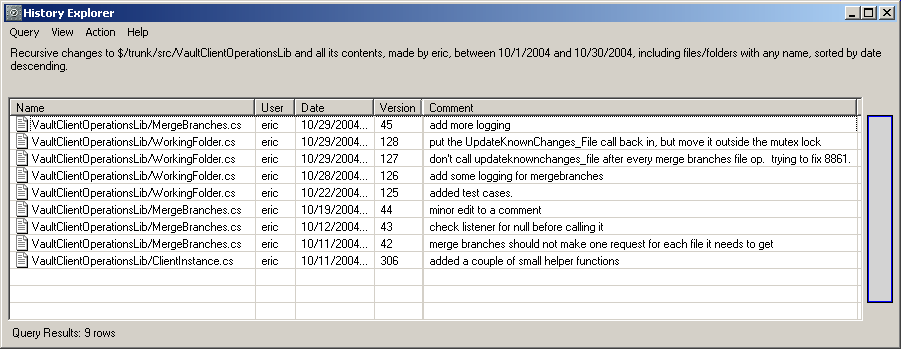
The following screendump from Vault shows all the changes I made to one of the Vault libraries during October 2004:
Best Practice: Do as I say, not as I do
It is while using the history features of an SCM tool that we notice what a lousy job our developers do on their checkin comments. Please, make your checkin comments as complete as possible. The screen dump above contains an example of checkin comments written by a slacker who was in too much of a hurry.
Sometimes the history features of your SCM tool are used merely to figure out what happened in the past, but often we need to dig even deeper. Perhaps we want to retrieve ("get") an old version? Perhaps we want to diff against an old version, or diff two old versions against each other? We may want to apply a label to a version that happened in the past. We may even want to use an old version as the starting point for a new branch. Good SCM tools make all of these things easy to do.
A word about changesets and history
For tools like Subversion and Vault which support atomic transactions and changesets, history can be slightly different. Because changesets are a grouping of individual changes, history is no longer just a flat list of individuals changes, but rather, can now be viewed as a hierarchy which is two levels deep.
To ease the transition for SourceSafe users, Vault allows history to be viewed either way. You can ask Vault's History Explorer to display individual changes. Or, you can ask to see a list of changesets, each of which can be expanded to see the individual changes contained inside it. Personally, I prefer the changeset-oriented view. I like the mindset of thinking about the history of my repository in terms of groups of related changes.
Blame
Vault has a feature which can produce an HTML view of a file with each line annotated with information about the last person who changed that line. We call this feature "Blame". For example, the following screen dump shows the Blame output for the source code to the Vault command line client:
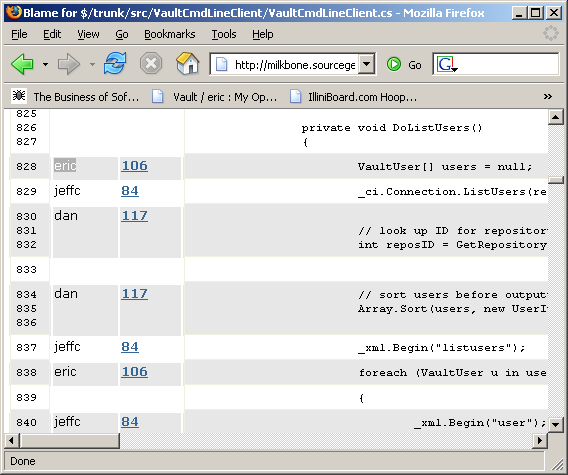
This poor function has had all kinds of people stomping through it. I was the last person to change line 828, which I apparently did in revision 106 of the file. However, line 829 was last modified by Jeff, and line 830 belongs to Dan.
Best Practice: Don't actually use the blame feature to be harsh with people about their mistakes.
Even though this Best Practice box is more about team management than source control, I don't feel like I'm straying too far off topic to offer the following tidbit:
Tim Krauskopf, an early mentor of mine, said many wise things to me, including the following piece of management advice which I have never forgotten:
"Spend more time on credit than on blame, and don't spend very much time on either one."
By now the reason for the silly-sounding name of this feature should be obvious. If I find a bug on line 832, the Blame feature makes it easy for me to see that it must be Dan's fault!
Note that we here at SourceGear take absolutely no credit or blame for the name of this command. We took our inspiration for this feature from the blame feature found in the CVS world, popularized by the Bonsai tool from the Mozilla project. The following screen dump shows this CVS Blame feature in action using the Bonsai installation on www.abisource.com. I was delighted to discover that the AbiWord layout engine actually still contains some of my code:
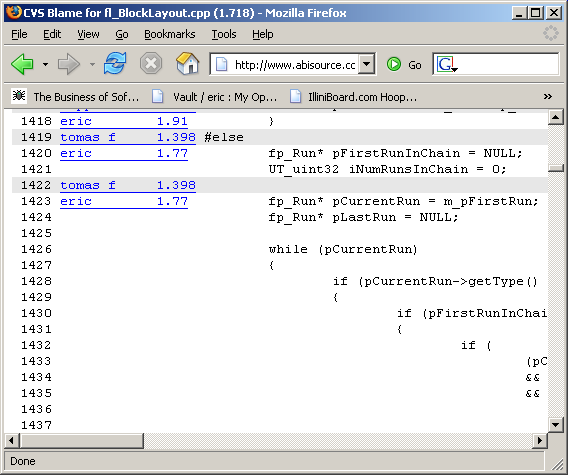
Whether you like the name or not, the Blame feature can be awfully handy sometimes.
Looking ahead
In the next chapter, we'll start talking about branches.
| < Chapter 5 | Chapter 7 > |