
2005-11-11 15:54:58
My life as a Code Economist
The six billion people of the world can be divided into two groups:
- People who know why every good software company ships products with known bugs.
- People who don't.
Those of us in group 1 tend to forget what life was like before our youthful optimism was spoiled by reality. Sometimes we encounter a person in group 2, perhaps a new hire on the team or even a customer. They are shocked that any software company would ever ship a product before every last bug is fixed.
Every time Microsoft releases a new version of Windows, major news services carry a story about the fact that the open bug count is a five digit number. People in group 2 find that sort of thing interesting.
The surprising truth is that a person in group 2 can lead a productive life. In fact, as with most any other kind of ignorance, they're probably happier that way.
The exception of course is if you are a software developer. That's an entirely different story. If you earn your living building shrinkwrap software products, you need to get yourself in group 1.
Perhaps, dear reader, you are a software developer in group 2? If so, I'm sorry I had to be the one to tell you this. I feel like I'm telling the neighbor kid that Santa Claus isn't real. :-)
Okay, seriously. I apologize for the mock arrogance of the previous paragraphs, and for the Santa Claus remark. I mean no condescension. Just like everybody else, I've got lots to learn. But I've also got lots of gray hair. Some people read my stuff because they want to benefit from the lessons I learned from all the stupid mistakes I made which caused that gray hair.
Which reminds me -- let me tell you a story...
In hindsight, releasing on Halloween probably wasn't such a good idea.
Last week was a terrible week at SourceGear. Most weeks I really enjoy my job. By the end of last week, I was reminding myself every hour that I get paid to do this.
Everything started out great on Monday, October 31st. It was the very first day in our new office space, and our whole company had a feeling of enthusiasm. We planned to release the Vault 3.1.3 maintenance release that day. It was ready the week before, but it didn't make sense to release it just before the move.
(Here at SourceGear, we ship a "maintenance release" of Vault whenever we want to provide our customers with bug fixes or other minor improvement. Our version numbering scheme is "Major.Minor.Maintenance". Version 4.0.7 would indicate that it is the seventh maintenance release since Vault 4.0. Historically, we have done one maintenance release each month or so.)
It started raining around noon. Those of us with children began to dread the prospect of going out to Trick-or-Treat in the rain. Still, a little bad weather wasn't enough to squash the mood. Our new office space is great, and we had a general feeling of confidence about 3.1.3. Vault 3.1 has been a really solid product. The 3.1.3 release contained several bug fixes, but none of them were really urgent. We shipped the release believing that it would be the last maintenance release for quite a while.
Unfortunately, things didn't work out that way at all. The 3.1.3 release introduced two new bugs.
But we didn't know that yet when we came in Tuesday morning wearing all smiles. The rain was gone and it was a beautiful fall day. Looking out my east window I could see the bright sun highlighting the colors of the autumn leaves on thousands of trees on the University of Illinois campus. With the relocation and the 3.1.3 release behind us, I looked forward to having the entire team focused on the development of Vault 4.0.
Then the groaning began. We found the first bug that morning: Something in 3.1.3 broke the ability for the client to store certain settings in the registry. It was a minor bug, but very annoying. Any user who changed their personal settings after installing 3.1.3 was going to lose those settings when we eventually released a fix.
The fix for this bug was easy. We really wanted to get it done quickly. The longer we left 3.1.3 out there, the worse it was going to be. So on Wednesday, we released version 3.1.4, containing nothing more than a fix for this client settings bug.
I'm a golfer, so I refer to this kind of situation as a "mulligan". In golf, a mulligan is basically a "do-over". You hit a bad shot, so you just ignore it and try again.
I hate mulligans. We shipped a maintenance release 48 hours after the previous one! This was just embarrassing, but we figured the best we could do was just forget about it and go back to work.
When we came to the office Thursday morning, the world didn't seem quite as wonderful as it did on Tuesday, but we were ready to be optimistic again. The mulligan was behind us. We told ourselves we wouldn't need another maintenance release for the rest of the year. Everyone went back to being busy developing the cool new features for Vault 4.0.
And then we discovered the second bug which was introduced in 3.1.3. The first bug caused groaning. This one provoked a few colorful metaphors. Here's the bug: Add a binary file to the repository. Branch the folder containing that file. Now try and retrieve that file from the branch. You can't. The Vault server returns an error.
This bug had to be fixed. There was no other alternative. Developers get kind of fussy when they can't get their files from the repository.
So on Friday we released Vault 3.1.5, the third maintenance release in a week. This felt like one of the lowest points in our company history. We started asking ourselves what went wrong.
Regression Testing
Clearly, this was a failure of "regression testing". I am a little hesitant use this term, as it makes me sound like a testing guru when I am not. The real experts in the field of software testing can speak at great length about the many different kinds of testing. There is unit testing, regression testing, integration testing, system testing, black box testing, white box testing, stress testing and that funky "Australian rules" testing where you have to hit the bug with your fist. These guys can pick any one of these types of testing and write an entire textbook on it.
Sometimes when I see all this jargon I break out in a Forrest Gump imitation:
"I'm not a smart man, but I know what testing is." (mp3)
I am definitely not a testing guru, but I know about regression testing. Regression testing is used to verify that you didn't accidentally break something. Regression testing is what you do to make sure that the product didn't accidentally get worse. Regression testing is the testing you do to prevent mulligans.
Despite the fiasco here at SourceGear last week, we do believe in regression testing. In fact, we use three different ways of verifying that our product isn't moving backwards:
- Automated tests. Our automated build system sends every Vault build through a suite of regression tests to verify that nothing got broken.
- Manual tests. Every build we release is manually examined by testers to verify that nothing looks broken.
- Dogfooding. We use our own product, so most of the time we catch problems before the bits ever leave the building.
Somehow, those two bugs slipped through all three of these safety nets. Evidently we need some more work in the area of regression testing.
- As luck would have it, we were already in the process of revamping our build system to use continuous integration. We originally started doing this because our customers want us to make sure that Vault works extremely well with CruiseControl.NET. But we will obviously gain the benefits internally as well. The concept makes enormous sense. If the product should "regress", we want to know as quickly as possible.
- So now we have a brand new automated build server which throws a hissy fit whenever something gets screwed up. It's an absurdly fast machine with dual-core Opterons and RAID disks. Our build/test time went from 45 minutes on the old machine to just 15 minutes now. We're also going to get one of those nifty build orbs that changes color whenever the build fails.
- Our next step is to write a few more regression tests to specifically deal with the situation from last week.
- Then we need to set up NCover. This will of course be a bad day. Code coverage is the perfect example of the old maxim that "things get worse before they get better". Everyone's experience with code coverage is basically the same. The first time you run code coverage, you are horrified because no matter how comprehensive you think your test suite is, the initial percent coverage is surprisingly low. That's the beauty of using code coverage -- it gives you a useful quantitative result to replace a qualitative guess which is almost always wildly optimistic.
- Finally, we need to start writing more regression tests and watch our percent coverage go up.
Our build and test practices were already very important to us. Now we're taking those practices to the next level.
However, and getting back to the place where this article started, sometimes the way to prevent mulligans is to not break the code in the first place.
An ounce of prevention...
So why would an ISV ever intentionally release a product with known bugs? Several reasons:
- You release with known bugs because you care about quality so deeply that you know how to decide which bugs are acceptable and which ones are not.
- You release with known bugs because it is better to ship a product with a quality level that is known than to ship a product which is full of surprises waiting to happen.
- You release with bugs because the alternative is to fix them and risk introducing more bugs which are worse than the ones you have now.
All of the reasons for such a decision are tied up in this one basic truth:
Every time you fix a bug, you risk introducing another one.
Every code change carries the potential for unintended side effects. Stuff happens.
Even as I write this, I miss the blissful ignorance of life in group 2. Don't we all start out with the belief that software only gets better as we work on it? The fact that we need regression testing is somehow like evidence that there is something wrong with the world. After all, it's not like anybody on our team is intentionally creating new bugs. We're just trying to make sure our product gets better every day, and yet, somewhere between 3.1.2 and 3.1.3, we made it worse.
But that's just the way it is. Every code change is a risk. A development cycle that doesn't recognize this will churn indefinitely and never create a shippable product. At some point, if the product is ever going to converge toward a release, you have to start deciding which bugs aren't going to get fixed.
To put it another way, think about what you want to say to yourself when look in the mirror just after your product is released. The people in group 2 want to look in the mirror and say this:
"Our bug database has ZERO open items. We didn't defer a single bug. We fixed them all. After every bug fix, we regression tested the entire product, with 100% code coverage. Our product is perfect, absolutely flawless and above any criticism whatsoever."
The group 1 person wants to look in the mirror and say this:
"Our bug database has lots of open items. We have carefully reviewed every one of them and consider each one to be acceptable. In other words, most of them should probably not even be called bugs. We are not ashamed of this list of open items. On the contrary, we draw confidence from this list because we are shipping a product with a quality level that is well known. There will be no surprises and no mulligans. We admit that our product would be even better if all of these items were "fixed", but fixing them would risk introducing new bugs. We would essentially be exchanging these bugs which we find acceptable for the possibility of newly introduced bugs which might be showstoppers."
I'm not talking about shipping crappy products. I'm not suggesting that anybody ship products of low quality. I'm suggesting that decisions about software quality can be tough and subtle, and we need to be really smart about how to make those decisions. Sometimes a "bug" should not be fixed.
Should we fix this bug or not?
There are four questions to ask yourself about every bug:
|
Question One |
When this bug happens, how bad is the impact? |
Severity |
|
Question Two |
How often does this bug happen? |
Frequency |
|
Question Three |
How much effort would be required to fix this bug? |
Cost |
|
Question Four |
What is the risk of fixing this bug? |
Risk |
Two of them are "customer questions", and the other two are "developer questions".
The Customer Questions: Severity and Frequency
For the first two questions, I like to visualize Severity and Frequency plotted on a 2D graph:
- The vertical axis is Severity.
- The top of the graph represents a bug with extremely
severe impact:
"This bug causes the user's computer to burst into flame." - The bottom of the graph represents a bug with extremely
low impact:
"One of the pixels on the splash screen is the wrong shade of gray." - The horizontal axis is Frequency.
- The right side represents a bug which happens extremely
often:
"Every user sees this bug every day." - The left side represents a bug which happens extremely
seldom:
"This bug only affects people who live in eastern Washington state and who have both Visual Studio 2003 and Visual Studio 2005 installed and it only happens during leap years on the day that daylight savings time goes into effect and only if the first day of that month was a Tuesday."
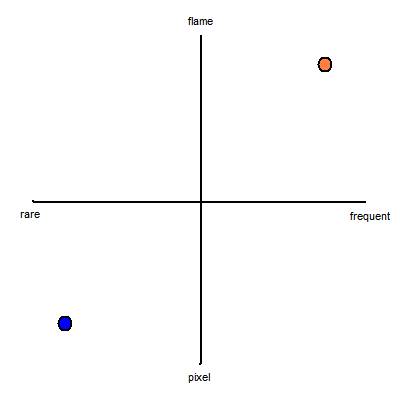
Try not to get hung up figuring out the exact line or curve which separates the bugs to be fixed from the bugs to be deferred. Speaking very broadly, stuff gets more important as you move up or to the right of the graph. The orange bug in the upper right should be fixed. The blue bug in the lower left should not.
This graph isn't terribly useful as a formal analysis tool for bug sorting. Attempts to be more quantitative are not likely to be productive. However, the graph can be helpful as a communication tool. Sometimes in a team discussion I actually draw this graph on a whiteboard when I am trying to argue for or against a certain bug.
The Developer Questions: Cost and Risk
Questions One and Two are about the importance of fixing a bug. Questions Three and Four are about the tradeoffs involved in fixing it.
Corollary: The answers to Questions Three and Four can only make the priority of a bug go down, never up. If after answering Questions One and Two it seems obvious that a given bug does not deserve attention, the other two questions should be skipped. A common mistake is in using Question Three to justify fixing a bug which isn't important. Don't make unimportant code changes just because they're easy.
The real purpose of these two questions is when you already know that the Severity and Frequency suggest that a given bug should be fixed. The questions about Cost and Risk are like a dialog box that says, "Are you sure?"
Every code change has a cost and a risk. Bad decisions happen when people make code changes ignoring these two issues.
Example: Item 6740
Vault stores all data using Microsoft SQL Server. Some people don't like this. We've been asked to port the back end to Oracle, PostgreSQL, MySQL and Firebird. This issue is in our bug database as item 6740. The four questions would look like this:
- Severity: People who refuse to use SQL Server can't use Vault at all.
- Frequency: This "bug" affects none of our current users. It merely prevents a group of people (those who refuse to use SQL Server) from using our product.
- Cost: Very high. Vault's back end makes extensive use of features which are extremely specific to Microsoft SQL Server. Contrary to popular belief, SQL isn't portable. Adapting the backend for any other database would take months, and the ongoing maintenance costs of two backends would be quite high.
- Risk: In terms of newly introduced bugs, the primary risk here lies in any code changes we would make to the server to enable it to speak to different back end implementations of the underlying SQL store.
Bottom line: This example is easy. It's obviously more of a feature request than a bug. Still we've talked about this, and the four questions play a part of the discussion.
Example: Item 10016
I told the story of Vault 3.1.3-4-5 mostly to illustrate the fact that code changes can have unintended side effects and that we need more regression testing. However, it is reasonable to discuss this fiasco in the context of my four questions.
As an example, consider the "can't fetch binary files after a branch" bug. We introduced this bug during an attempt to fix bug 10016, another bug which involves a problem with conversion of End-Of-Line terminators for Linux and MacOS users. The four questions for this EOL bug would have looked something like this:
- Severity: For a certain class of users, this bug is a showstopper for their use of Vault. It does not threaten data integrity, but it makes Vault unusable.
- Frequency: This bug only affects users on non-Windows platforms, currently a rather small percentage of our user base.
- Cost: The code change for this bug is small and appears simple.
- Risk: We obviously thought the risk here was low. Hindsight is 20/20. :-)
If regression testing had told us that the Risk was higher than we thought, we would have revisited the four questions. Because the Frequency is relatively low, we might have decided to defer this bug fix until we figured out how to do it without breaking things.
In fact, that's what we ended up doing. In the 3.1.5 release last Friday, we simply un-did the fix for bug 10016. Bug 10016 is now "open" again. A 3.1.6 maintenance release is therefore probably on the way. :-(
Example: Item 4860
From an idealist's point of view, a nice feature of a version control system is the fact that nothing ever really gets deleted. Your repository is a complete archive of every checkin which has ever occurred.
But in real life, sometimes you actually do want to pretend that something never happened. For these situations, Vault has a feature called Obliterate. Unlike the Delete command, which doesn't really delete anything, the Obliterate command is destructive.
Bug 4860 basically says that our Obliterate command is slow.
- Severity: Obliterate is slow. Really slow.
- Frequency: Obliterate is not a command which is used every day. Still, most users need it once in a while.
- Cost: The effort required is very close to a complete rewrite of the feature. Ballpark estimate: One developer, code complete in a month.
- Risk: Stunningly high. This is the only feature in our product which destroys anything. Every other aspect of Vault was designed with a pathological paranoia over loss of data.
Bug 4860 is a real pain the neck. Users gripe about it, and we totally understand why. However, in terms of Severity and Frequency, we're only talking about slow performance of a feature which is not frequently used. When you add Risk to the discussion, it suddenly becomes easy for our developers to procrastinate on bug 4860 and find something else more urgent to do. The current implementation of this feature is slow as molasses, but it is known to be safe. We are terrified of touching it.
Nonetheless, this bug is on the schedule for Vault 4.0. A product in its 4.0 release should be more polished and refined than it was at 2.0. I am not fond of this feature, but I admit that bug 4860 is valid and its time has come.
Market Context
Some of you already think I am making this issue far too complicated. If so, you're not gonna like this next part.
Not only do you have to answer the four questions, but you have to answer those questions with a good understanding of the context in which you are doing business. Markets vary. Each has its own competitive pressures and quality expectations. You need to understand two things:
- Understand the Quality Expectations of your market segment.
- Understand what the Market Window is for your product.
I'm probably going to get flamed for saying this, but it's the truth, so here it is: The reason we can ship products with "bugs" is that there are "bugs" that customers will find acceptable. Nobody wants a crappy product, but that doesn't mean that everybody expects every product to be utterly perfect.
Quality Expectations
Different market segments have different expectations about product quality. People who write code for the space shuttle are dealing with higher quality standards than people who write casual games.
Years ago I worked as part of a team where the quality standards were incredibly high. We were building software which was burned into the ROM of consumer cell phones. This is a world where mulligans are not an option. You only get one chance to burn that ROM. Life is unbelievably bad if you discover a serious bug just after your software shipped inside a million phones. Our development cycles were incredibly long, since most of the time was spent testing and bug-fixing until the code coverage level was well over 90% and the traceability matrix was complete.
At SourceGear we build and sell version control tools. People use our product to store and manage their own source code. The quality expectations in our market are extremely high, but there is still a gap between those expectations and perfection. Understanding those expectations is an important part of our decision-making. A bug which affects the safety of our customers' data is obviously going to be prioritized higher than anything else.
The fact is that last week's mistakes are not going to be fatal for SourceGear. In fact, in a bit of irony, it was our highest revenue week ever. :-)
What happened last week was embarrassing and frustrating, but the company will certainly survive. The bugs we introduced in 3.1.3 were a potential inconvenience for our customers, but their data was never threatened, and since they download Vault releases over the Internet, it's relatively simple for us to release fixes. After three maintenance releases in five days, we swallowed our pride, briefly acknowledged how happy we are that Vault is not burned into the ROMs of a cell phone, and start figuring out how to prevent mulligans in the future.
Market Window
We all know what happens if a product falls short of the customers' quality expectations. For some ISVs, this is a problem, but most developers naturally have a sense of craftsmanship and pride in their work. Good developers want to exceed the quality standards of their customers.
But is it possible to make a mistake by going too far? Can we err by exceeding the quality standards of our customers too much? Why would anyone mind if we shipped a product which was higher quality than the market needs?
If quality could be obtained without tradeoffs, there would be no problem. However, time is always a constraint. There is a "market window" for your product, and it is closing. After a certain point, the market doesn't want your product anymore. It's too late.
And product quality takes a lot of time. Increases in the quality of your product tend to become an exercise in constantly diminishing returns. Which of the following choices makes more sense?
- Deliver a product today with a quality level that your market considers acceptable.
- Deliver a product one year later with a quality level that is higher than your market requires.
Choosing the second option gives you the warm and fuzzy feeling of building a really high quality product. This is a cool thing. Good developers must have a sense of pride in their craftsmanship, and nothing I say should be construed to diminish the importance of that.
Furthermore, having a higher quality product offers competitive benefits. All else equal, fully informed customers will choose the higher quality product.
But the fact is that shipping a year later means missing out on a year of important benefits, not the least of which is revenue. In most market segments, there is a competitor who is ready and willing to help customers while you spend that year climbing the asymptotic hill toward product perfection. Congratulations on building a product which makes you feel good. Unfortunately, your ISV is now dead.
Remember, I'm not arguing for crappy software. I'm arguing that building products to please yourself instead of your customers is always a mistake.
Quality and craftsmanship are incredibly important. If you're going to err to one side of this issue, obviously you should go for more quality, not less.
But black-and-white perfectionist thinking will kill your ISV. Most people can intuitively recognize that there is no such thing as a software product which is absolutely 100% perfect. A central skill of managing an ISV is making tough decisions about exactly how your product is going to miss perfection.
Eric, why are you making this so complicated?
I'm not the one making this complicated -- it got that way all by itself. :-)
I know what you want. I want it too. I want a way to make all these decisions easy. I want an algorithm with simple inputs that tells me which bugs I should fix and the order in which I should fix them.
I want to implement this algorithm as a feature in our bug-tracking product and make gigabucks selling it to all those people who think they can save money by hiring software development managers that are devoid of clue. Wouldn't this be a killer feature?
- In the Project Settings dialog, the user would enter a numeric value for "Market Quality Expectations" and a specific schedule for the closing of the "Market Window".
- For every bug, the user would enter numeric values for Severity, Frequency, Cost and Risk.
- The Priority field for each bug would then be automatically calculated. Sort the list on Priority descending and you see the order in which bugs should be fixed. The ones near the bottom will have a Priority less than zero, indicated that they should not be fixed at all.
Heck, I'd probably even patent this algorithm. I have long suspected that I am a complete hypocrite on the issue of software patents. In principle, I believe that software patents are fundamentally evil, but my ethics would probably do a 180 if I had a patent which allowed me to purchase a Gulfstream jet. :-)
Alas, this ethical quandary isn't going to happen, as "Eric's Magic Bug Priority Algorithm" does not exist, and it never will. There is no formula to make this easy. Figuring out exactly how your product is going to be imperfect is hard. It should be hard.
The bad news is that there is no shortcut. Understand your context, ask all four questions, and use your judgment.
The good news is that experienced developers can usually make these decisions very quickly. In many cases, it only takes a few seconds to mentally process the four questions and make a decision. In the tougher cases, gather two coworkers near a whiteboard and the right answer will probably show up soon.
Eric Sink, Code Economist
The title on my business card says "Software Craftsman", a choice which reflects my preference for speaking of software development in terms of craftsmanship rather than engineering or art.
But I admit that my metaphor is not a perfect match. Comparing shrinkwrap software development to handcrafts doesn't adequately reflect the part of my job which requires tough decisions. A cross-stitch piece can be perfect. A non-trivial software product cannot.
For this reason, I also like to compare shrinkwrap software development to macroeconomics. It's an optimization problem. Every choice involves tradeoffs. Success is not found by building a perfect product, but rather, by finding a perfect set of compromises.
Apparently Federal Reserve chairman Alan Greenspan is going to be out of work in a couple months. Perhaps he should consider a career in software? He might be good at it. :-)